It started, as so many things do, with a tweet (this one from Kent Beck):
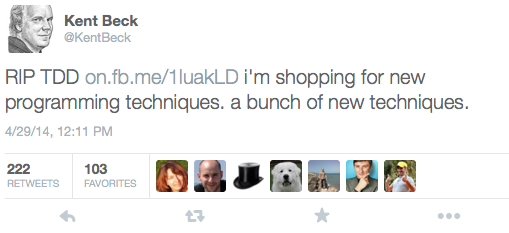
The link in that tweet points to an entry on Kent’s Facebook page, which in turn references a blog entry by someone named David Heinemeier Hannson, titled TDD is dead. Long live testing.:
Test-first fundamentalism is like abstinence-only sex ed: An unrealistic, ineffective morality campaign for self-loathing and shaming.
Kent’s response:
I’m sad, not because I rescued [TDD] from the scrapheap of history in the first place, but because now I need to hire new techniques to help me solve many of my problems during programming
Kent then lists a number of things that he gets from Test Driven Development. I paraphrase many of those items here because they’re many of the things that I get from practicing TDD:
- Avoiding over-engineering: By not implementing any new features until I have a need for them (as evidenced by a newly written failing unit test), I keep myself from coding things that I currently think I’ll need in the future, but that end up never being used.
- Rapid API feedback: Creating a new Application Programming Interface (API) one test at a time helps me keep the API usable. After all, if I can’t code a test that exercises a method, how should I expect anyone else to use that method in their code?
- Rapid detection of logic errors: I’m human. I make mistakes. I even make mistakes while writing code. With TDD, the automated unit tests catch those mistakes quickly and cheaply.
- Documentation: While I don’t automatically get a beautifully written, lavishly illustrated users manual from applying TDD, I do get a nice suite of automated unit tests, each of which shows the folks who will be working with this code in the future exactly how I intended the implemented code to be used.
- Avoiding feeling overwhelmed: Every once in a while I get stuck trying to figure out how to implement something. However, assuming the tool support exists, I can pretty much always figure out how to write a test to prove that something is or is not implemented. Writing that test lets me make some progress in the face of what may feel overwhelming, and often gives me that missing bit of insight needed to implement the feature.
One thing Kent did not mention, but that I’ve personally found hugely valuable, is the way I can use TDD (and the resulting suite of automated unit tests) to uncover problems in the specified requirements. Suppose one is writing a program to assign accounting codes to medical claims depending on such factors as the type of provider, type of medical service provided, the patient’s insurance type, the date of the claim, etc. Suppose further that one is given the rule “all alcoholism-related claims are to be assigned code 90116”. One writes a test to see that an alcoholism-related claim is assigned code 90116; then one runs the test suite and finds that the test fails (because no one has implemented that logic yet). One implements the logic and reruns the test suite. The new test passes, but an older test stating that all claims for members of ASO plans are to be assigned code 31000 fails. One reviews the requirements and discovers that, in fact, they state that:
- all claims must be assigned to one and only one code
- all ASO claims must be assigned to 31000
- all alcoholism claims must be assigned to 90116.
Clearly, there’s something wrong in the requirements, although at this point one cannot say for certainty what that something is. But, with TDD, I’ve discovered these sort of problems within moments of trying to implement something. With a test-last approach, I won’t find these sorts of problems out until after I’ve already implemented the inconsistent requirement. If I’m lucky, I’ll find them out before the code gets handed off to someone else for testing; if not, I’ll probably not find them until the fixes go live and screw up the general ledger accounts.
TL;DR? I’m still doing TDD. Because reasons.